Mire jó a HierarchyID? Vannak műveletek, amelyeket gyorsabban lehet végrehajtani a segítségével, mivel a node-ok elérési útja van enkódolva az idben, így a felindexelt id alapján egyes lekérdezések hatékonyak lehetnek.
Nézzük meg pl. hogyan keresnénk meg egy adott ember összes direkt vagy indirekt beosztottját? Azaz, az adott node alatti részfát szeretnénk kiválasztani (az előző rész adataira alapozok).
declare @manager hierarchyid = (select OrgNode from HumanResources.NewOrg where LoginID = 'adventure-works\terri0') --select @manager.ToString() select cast(OrgNode as varchar(50)) as OrdPath, EmployeeID, LoginID, ManagerID, Title from HumanResources.NewOrg where @manager.IsDescendant(OrgNode) = 1 order by OrdPath
Kikeressük terri0 HierarchyID-jét, majd az IsDescendant metódus segítségével leszűrjük az utódait. Gyerekek, unokák, stb. (kicsit bizarr, hogy pont Terri nevű emberről szól a példánk… :). A függvény magát a kiinduló node-ot is visszaadja, azaz a DescendantOrSelf név precízebb név lenne (persze ez egy CTP verzió, ki tudja, hogy lesz még a véglegesben).
A kimenet:
OrdPath EmployeeID LoginID ManagerID Title ------------------------------ ----------- ------------------------------ ----------- ------------------------------ /2/ 12 adventure-works\terri0 109 Vice President of Engineering /2/1/ 3 adventure-works\roberto0 12 Engineering Manager /2/1/1/ 4 adventure-works\rob0 3 Senior Tool Designer /2/1/2/ 9 adventure-works\gail0 3 Design Engineer /2/1/3/ 11 adventure-works\jossef0 3 Design Engineer /2/1/4/ 158 adventure-works\dylan0 3 Research and Development Manag /2/1/4/1/ 79 adventure-works\diane1 158 Research and Development Engin /2/1/4/2/ 114 adventure-works\gigi0 158 Research and Development Engin /2/1/4/3/ 217 adventure-works\michael6 158 Research and Development Manag /2/1/5/ 263 adventure-works\ovidiu0 3 Senior Tool Designer /2/1/5/1/ 5 adventure-works\thierry0 263 Tool Designer /2/1/5/2/ 265 adventure-works\janice0 263 Tool Designer /2/1/6/ 267 adventure-works\michael8 3 Senior Design Engineer /2/1/7/ 270 adventure-works\sharon0 3 Design Engineer
Az OrdPathból jól látható, de az EmployeeID-k és ManagerID-k alapján szemre is kikereshető, hogy az összes utód szerepel a listában.
A lekérdezés költségének elemzéséhez kiveszem az OrdPath oszlopot, és a order by-t is, hogy tisztán a szűrés költségét lássuk. Illetve rakok egy indexet a LoginID oszlopra, hogy az első sor szűrése gyors legyen:
create nonclustered index IDX_LoginID on HumanResources.NewOrg(LoginID)
A csupasz lekérdezés:
declare @manager hierarchyid = (select OrgNode from HumanResources.NewOrg where LoginID = 'adventure-works\terri0') select EmployeeID, LoginID, ManagerID, Title from HumanResources.NewOrg where @manager.IsDescendant(OrgNode) = 1
A végrehajtási terv:
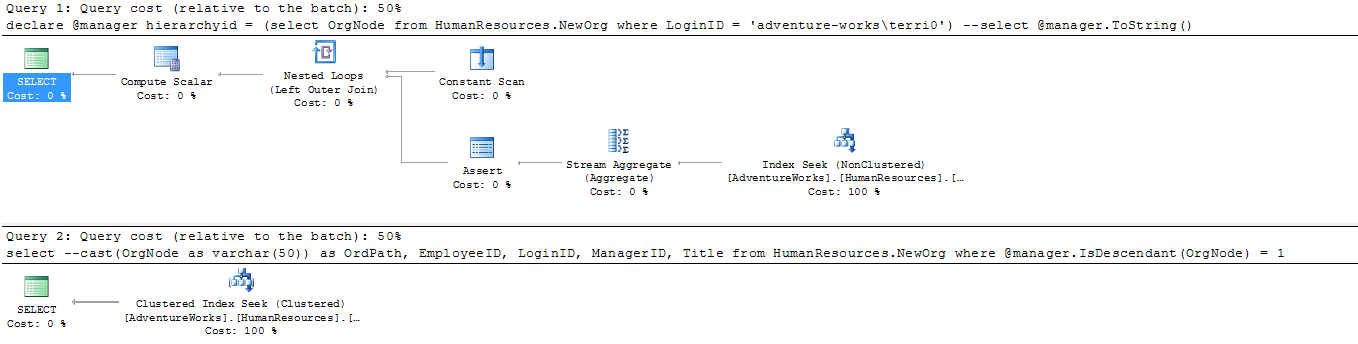
Mint látható (kattintani kell a képre) az IsDescedantra fel van készítve az optimizer (!), és a lekérdezést a leghatékonyabb módon, index seek-kel hajtja végre (alul, jobb oldalt). Nézzük meg a szűrőfeltételt is az index operátorhoz:
Seek Keys[1]:
Start: [AdventureWorks].[HumanResources].[NewOrg].OrgNode >= Scalar Operator([@manager]),
End: [AdventureWorks].[HumanResources].[NewOrg].OrgNode <= Scalar Operator([@manager].DescendantLimit())
[/source]
Látható, hogy kihasználja azt, hogy az összes utód egy bagázsban van, mivel az OrdPath így van rendezve (emlékezzünk az előző részből, a HieararchyID oszlopunkon volt egy clustered index: constraint PK_NewOrg_OrgNode primary key clustered (OrgNode)). A DescendantLimit egy belső függvény, ez jelzi, hol váltanak szintet, meddig kell keresni. Ügyes. A lekérdezés költsége minimális, az első és a második rész összege 6.6 ms (két index seek). Persze, az igazán izgalmas, mekkora ennek a költsége a rekurzív CTE megoldáshoz képest, ami így nézne ki:
[source='sql']
with Descendants(EmployeeID, LoginID, ManagerID, Title)
as
(
select EmployeeID, LoginID, ManagerID, Title
from HumanResources.NewOrg
where LoginID = 'adventure-works\terri0'
union all
select
e.EmployeeID,
e.LoginID,
e.ManagerID,
e.Title
from HumanResources.NewOrg as e
join Descendants as d
on e.ManagerID = d.EmployeeID
)
select * from Descendants
[/source]
Legyünk igazságosak, a HieararchyID oszlopon volt egy clustered index, az persze megbikázta a lekérdezést mint állat. Szegény CTE-s megoldásunk meg join-ol keményen, kapjon hát hozzá olyan indexeket, amelyek rendesen megtámogatják. Mivel a ManagerID nem túl szelektív (egy adott ManagerID-re a tábla jelentős része visszajöhet), ezért annak included column-ot is tartalmazó nc indexet adok, hogy cover query-t tudjon csinálni a szerver.
[source='sql']
create unique nonclustered index IDX_EmployeeID
on HumanResources.NewOrg(EmployeeID)
go
create nonclustered index IDX_ManagerID
on HumanResources.NewOrg(ManagerID) include (EmployeeID, LoginID, Title)
[/source]
(Finomság: az OrgNode nincs benne az indexben, mivel az a clustered index kulcsa, így mindenképpen benne van minden nc indexben is, így kár lenne kétszer belerakni.)
Ezen megoldásban a kimenet sorrendje más, de az adatok benne ugyanazok, és mivel most is csak a szűz lekérdezés költségére koncentrálunk, az order by-t itt is kihagytuk.
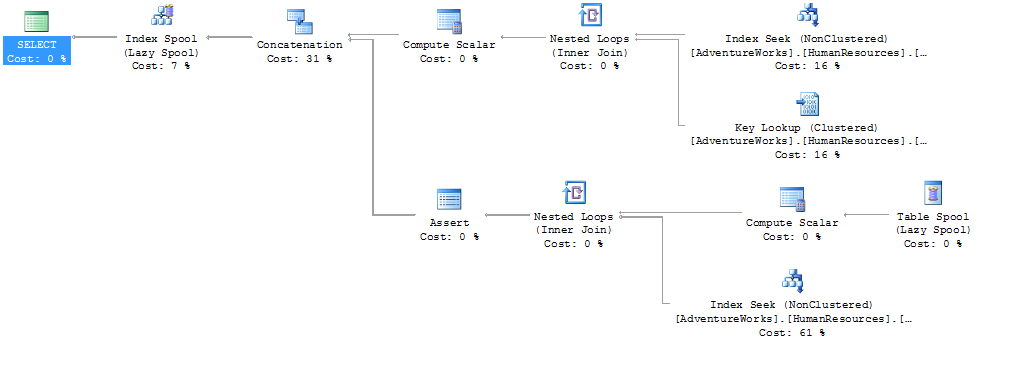
A terv költsége 21 ms. Ezekkel az adatokkal a HierarchyID-s megoldás 3x gyorsabb. Minimum, ugyanis míg az első megoldás 5 lapolvasást igényelt, a CTE-s 118-at, és még egy temp táblát is használt! A gyakorlatban ez azt jelenti, hogy terhelt szervernél sokkal lassabb lesz, mint a 3-as szorzó.
Összegezve, ha egy node utódjait reprezentáló részfát akarunk leválogatni, akkor egy rendesen karbantartott és felindexelt HierarchyID oszlop hatékony lekérdezéseket tesz lehetővé, hatékonyabbat, mint a hagyományos rekurzív megoldás.
Zárásul egy figyelmeztetés. NEM minden esetben gyorsabb a HierarchyID a hagyományos rekurzív kompozícióval szemben, szóval ne halljam vissza, hogy soci azt mondta, dobjuk ki a ManagerID-t, és használjunk HiearchyID-t. Nem, a következő részben mutatok olyan esetet, amikor a hagyományos relációs megoldás gyorsabb. Nyilván olyan lekérdezést kell megfogalmazni, ami nem tudja kihasználni a HiearchyID mélységi bejárás alapú indexelését.
Could you hire me? Contact me if you like what I’ve done in this article and think I can create value for your company with my skills.
LEAVE A COMMENT
7 COMMENTS
Jópofa dolog ez a hierarchyID, mindenképpen áttekinthetőbbé teszi a kódot, meg a próba-lekérdezéseket is egy fából. Engem általában még az szokott zavarni, hogy egy parent/managerID-s táblát nagyon kényelmetlen kézzel módosítgatni az SQL IDE-ről. Erre van esetleg valami tipped, hogyan érdemes?
Még a sima táblákat se mindig egyszerű, nem is erre való az SQL IDE.
Hiearchiákhoz valami custom app kell, másként kézzel nehéz belemászni.
télleg törölve lett innen a korábbi “hozzászólásom”?
Tudatosan biztos nem, de a spamfilter belenyúlhatott. Utánanézek a kukában.
Nincs a kukában, de 5 nap után törlődnek belőle a tételek, ha korábban írtál, és a spamba került, akkor annak már sajnos lőttek.
csak írtam egy mailt, azt szerettem volna megkérdezni, megkaptad-e, illetve – ha nem – akkor hová írhatok, amit el is olvasol :)
zsolt.soczo kukac gmail.com.
Ezt állandóan olvasom. :)